serverless_0">3 serverless数据分析
大纲
- 3 serverless数据分析
- 3.1 创建Lambda
- 3.2 创建API Gateway
- 3.3 结果
- 3.4 总结
3.1 创建Lambda
在Lambda中,我们将使用python3作为代码语言。
| 步骤 | 图例 |
|---|---|
| 1、入口 | 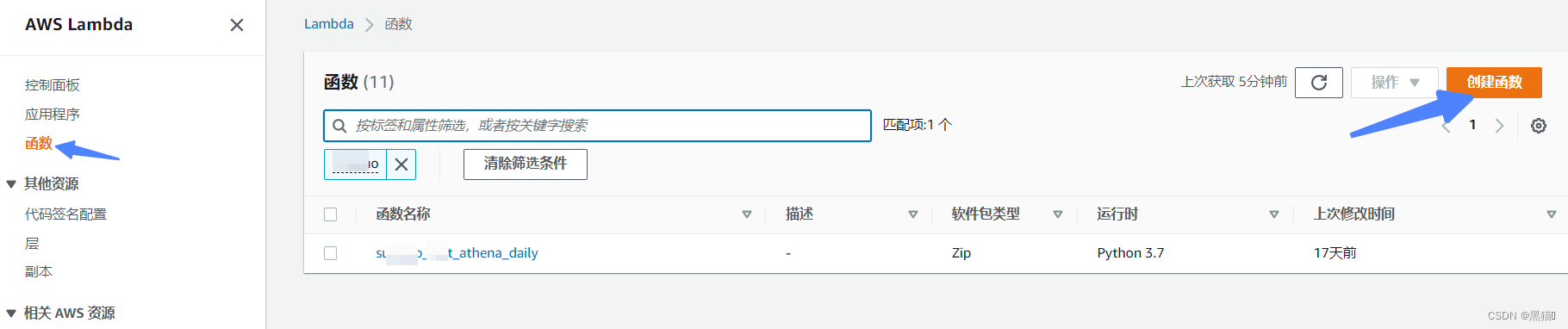 |
| 2、创建(我们选择使用python3.7) | 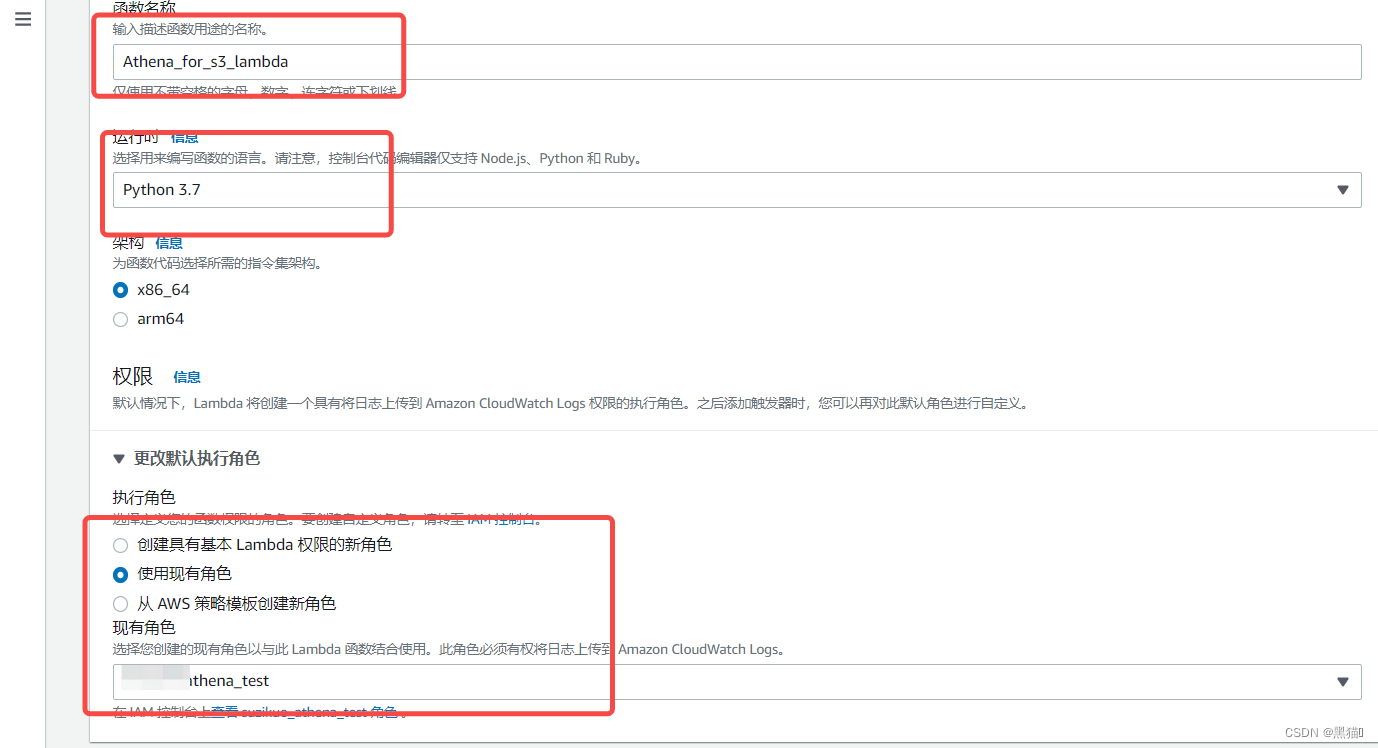 |
| 3、IAM权限(权限可信实体需要包括Lambda才能将角色绑定到Lambda上) |  见下方“IAM可信实体描述” 见下方“IAM可信实体描述” |
| 4、指定处理函数(处理程序要为用户程序的入口) |  |
| 5、添加层(层为我们的代码运行时的环境,并且,兼容运行时要包含上一步中的运行时环境) |  |
| 6、代码(在此代码中使用了boto3来连接Athena,可自定义sql,使用方法请看官方文档) | 见下方“Lambda代码” |
IAM可信实体描述:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Lambda代码
import boto3, os, json
import pandas as pd
from pyathena import connect
import time
REGION = "us-west-2"
# expected request: anomaly/{meter_id}?data_start={}&data_end={}&outlier_only={}
def lambda_handler(event, context):
ATHENA_OUTPUT_BUCKET = "【待替换S3桶路径】/athena"
DB_SCHEMA = "suzikuo_test_db"
USE_WEATHER_DATA = 0
pathParameter = event["pathParameters"]
queryParameter = event["queryStringParameters"]
METER_ID = pathParameter['meter_id']
DATA_START = queryParameter['data_start']
DATA_END = queryParameter['data_end']
OUTLIER_ONLY = queryParameter['outlier_only']
query = '''
select * from "{}".reading_type_int
where meter_id = '{}'
and cast(reading_date_time as timestamp) >= timestamp '{}' and cast(reading_date_time as timestamp) < timestamp '{}'
'''.format(DB_SCHEMA, METER_ID, DATA_START, DATA_END)
athena = boto3.client('athena')
response = athena.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': 'suzikuo_test_db'
},
ResultConfiguration={
'OutputLocation': 's3://suzikuo-test-2022-8-4-s3/athena',
'EncryptionConfiguration': {
'EncryptionOption': 'SSE_S3'
}
}
)
while True:
try:
query_results = athena.get_query_results(
QueryExecutionId=response['QueryExecutionId']
)
break
except Exception as err:
if 'Query has not yet finished' in str(err):
time.sleep(3)
else:
raise(err)
return query_results['ResultSet']['Rows']
3.2 创建API Gateway
使用API Gateway+Lambda 可轻松实现一个serverless架构。
| 步骤 | 图例 |
|---|---|
| 1、入口 |  |
| 2、API(我们使用的是Lambda,所以选HTTP API) | 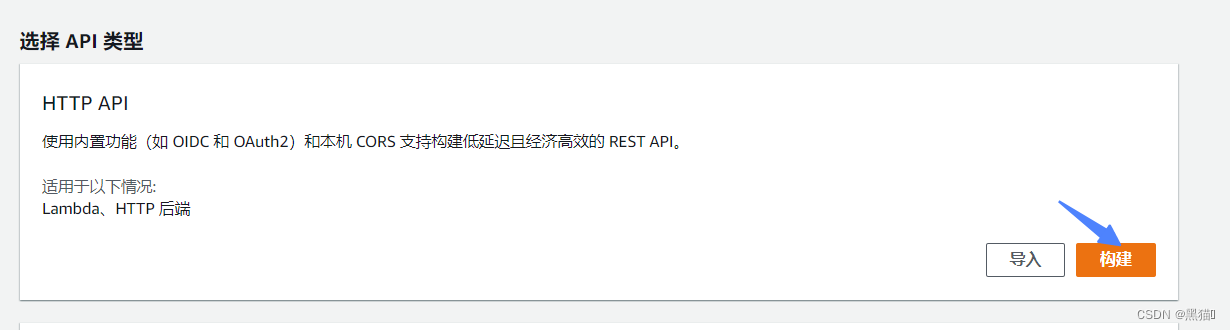 |
| 3、创建集成(指定要绑定的Lambda) | 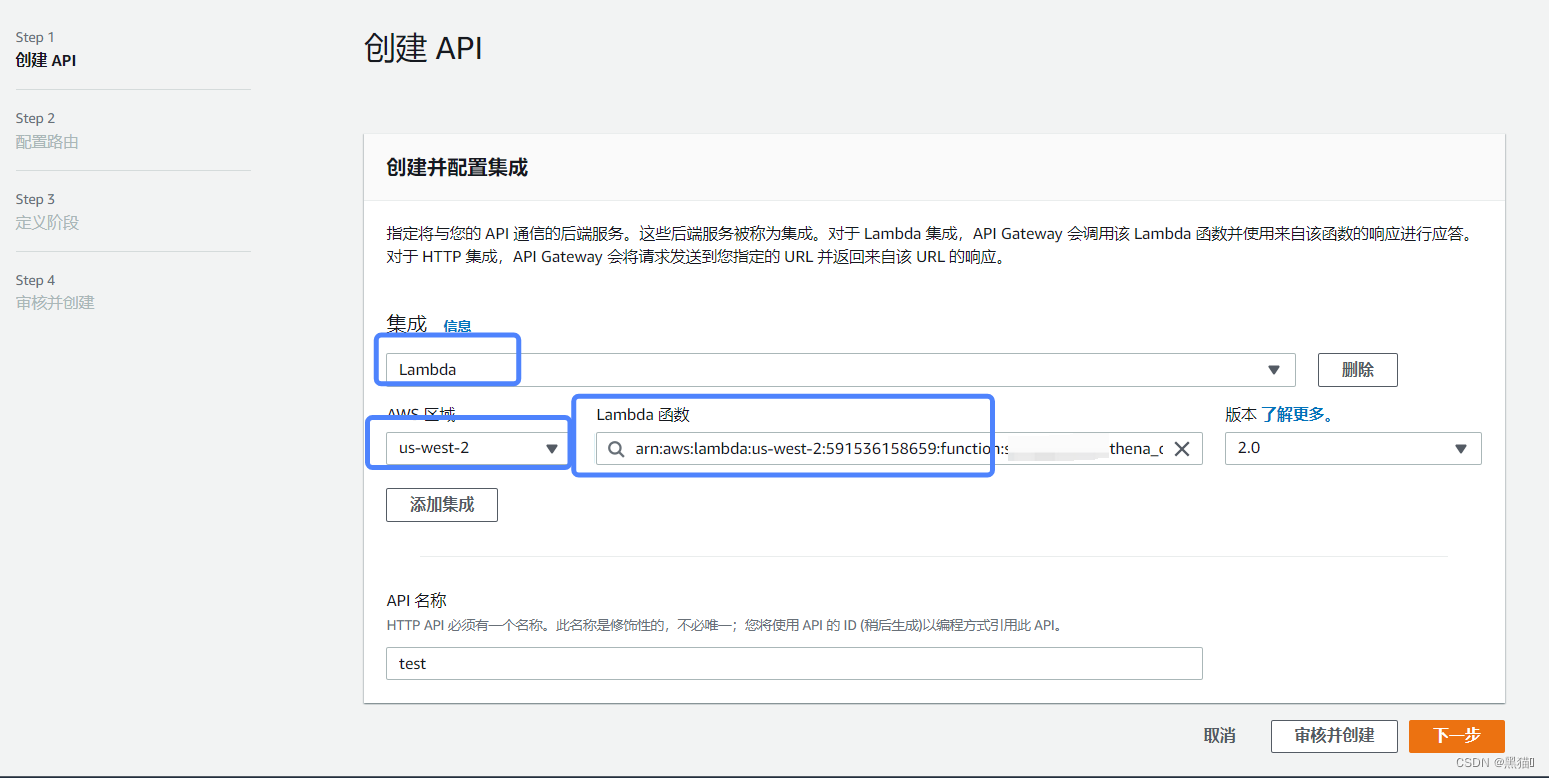 |
| 4、配置路由(指定路由要请求的集成(lambda)) | 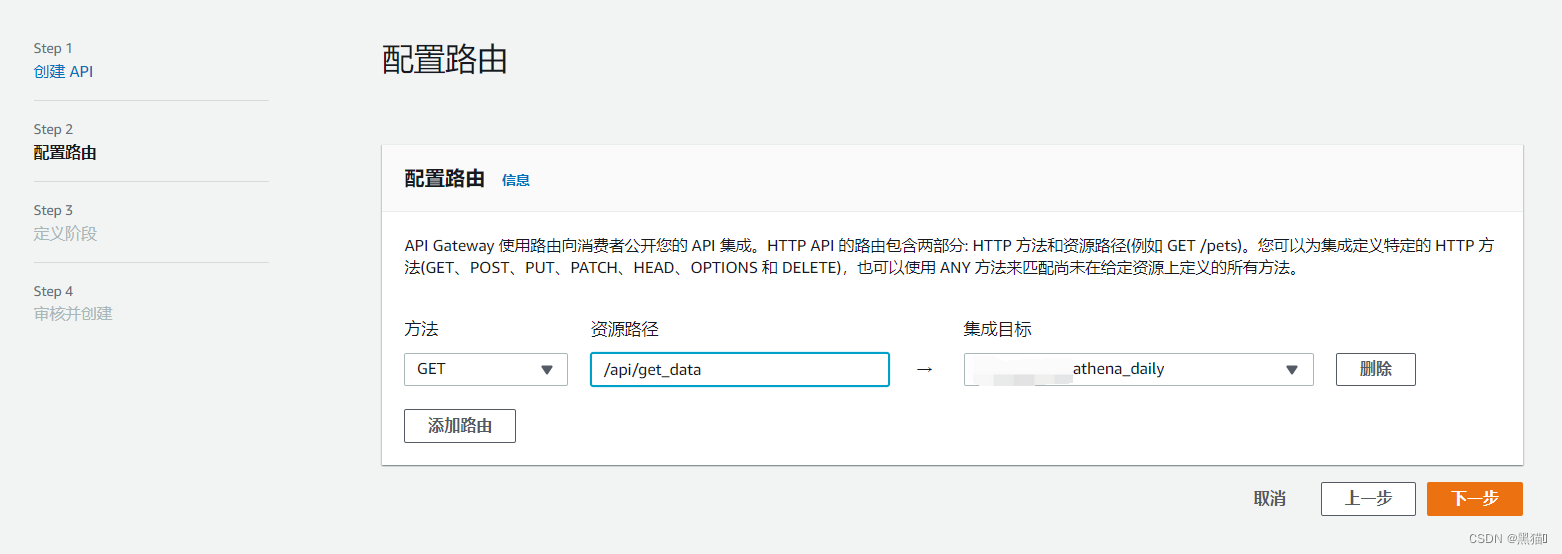 |
| 5、一直下一步即可 |
3.3 结果
此案例只查询了某一ID的某个时间段内的数据
通过获取URI和参数,在Lambda中编写逻辑,可以实现我们对数据的任意操作。
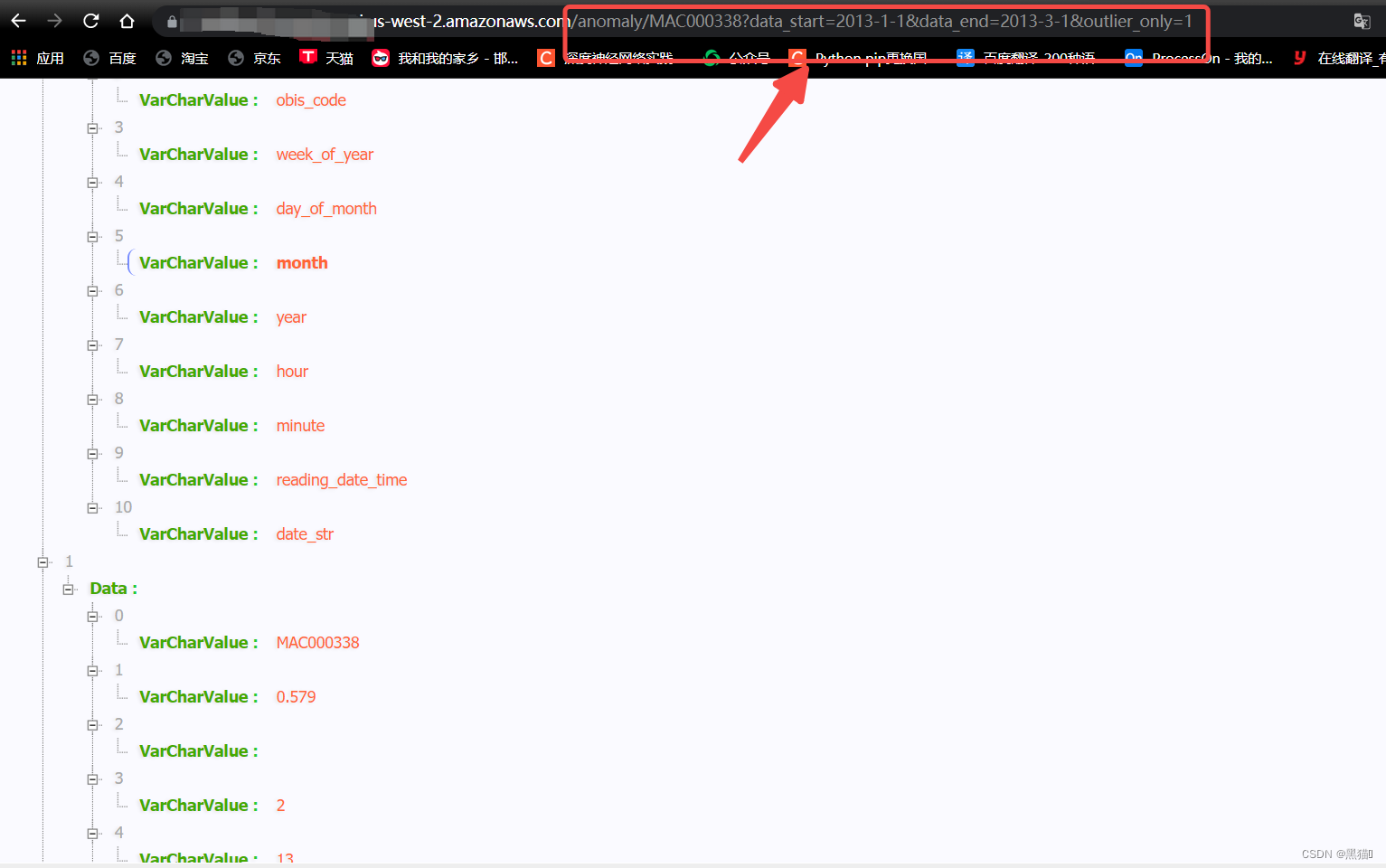
3.4 总结
到此,我们已经完成了基于Glue ETL(提取、转换和加载)的serviceless 数据分析的全部过程了。在此案例中,我们使用到了AWS 服务中的Glue、S3、APIGateway、Lambda等服务实现了一个通过API访问的数据统计与分析接口。